robots.txt KI-Crawler steuern bedeutet 2026 deutlich mehr als «GPTBot blockieren» und fertig. Hinter diesem Satz versteckt sich eine Drei-Klassen-Entscheidung: Welche Bots crawlen für KI-Trainings? Welche indexieren für KI-Suche? Und welche handeln direkt im Auftrag von Nutzern? Wer diese drei Kategorien verwechselt, blockiert im schlimmsten Fall die Bots, die für Zitierungen in ChatGPT, Claude und Perplexity sorgen — und lässt genau die durch, die Inhalte als Trainingsdaten verwerten. Dieser Beitrag liefert die Tabelle aller 14 relevanten Bots mit User-Agent-Strings, eine Entscheidungs-Matrix nach Schweizer Geschäftstypen und 4 einsatzbereite robots.txt-Vorlagen.
Training, Search oder User-Action — die drei Klassen, die alles entscheiden
Die meisten robots.txt-Ratgeber behandeln KI-Crawler als homogene Gruppe. Das ist das Grundproblem. Tatsächlich gibt es drei funktional verschiedene Typen, die mit denselben Zugangsentscheidungen grundlegend unterschiedliche Konsequenzen haben.
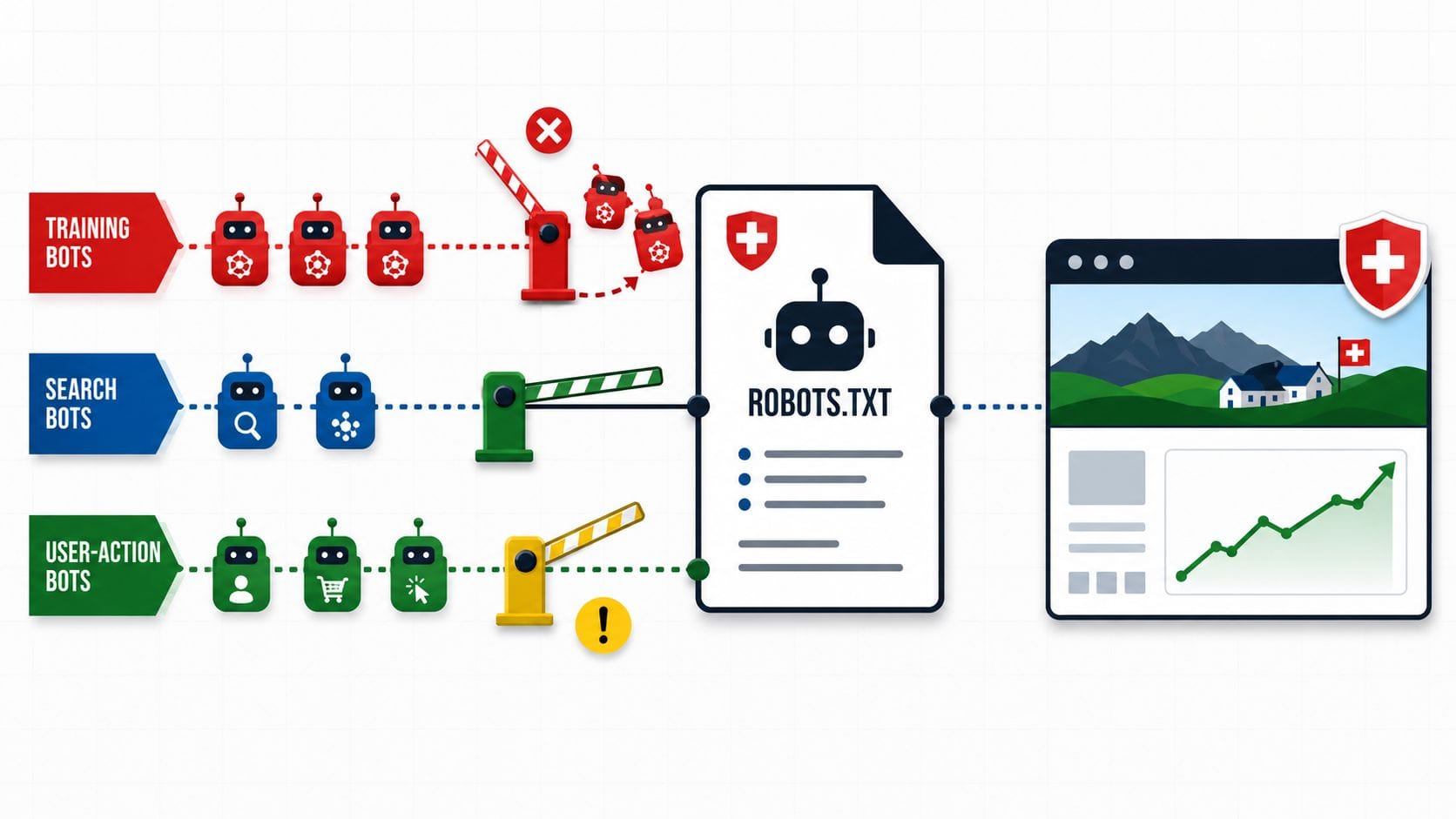
Training-Crawler sammeln systematisch Webinhalte, um damit Sprachmodelle zu trainieren. Sie laufen in Wellen, oft als Batch mit mehreren hundert Seiten pro Tag. Wer diese Bots blockiert, sagt: «Meine Inhalte dürfen nicht als Trainingsgrundlage verwendet werden.» Das ist ein legitimes Opt-out — und für Unternehmen mit proprietärem Content, Beratungswissen oder vertraulichen Fachinhalten durchaus sinnvoll. Zu dieser Gruppe gehören GPTBot, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Meta-ExternalAgent und Amazonbot.
Such-Crawler indexieren Inhalte, um sie für Antworten in KI-gestützten Suchsystemen nutzbar zu machen — also für ChatGPT Search, Perplexity, Claude und ähnliche Angebote. Wer diese Bots blockiert, sagt: «Ich möchte in KI-Antworten nicht zitiert werden.» Für die grosse Mehrheit der Schweizer KMU ist das kontraproduktiv. Hierzu gehören OAI-SearchBot, PerplexityBot und DuckAssistBot.
User-Action-Bots greifen auf eine Seite zu, wenn ein Nutzer in einer KI-Anwendung aktiv eine Frage stellt, die eine aktuelle Quelle erfordert. Sie sind kein regelmässiger Crawler, sondern ein Proxy für echte Nutzeranfragen. Diese Kategorie wuchs 2025 um das 15-Fache — von praktisch null auf rund elf Prozent aller KI-Bot-Requests. Zu dieser Gruppe gehören ChatGPT-User, Claude-User und Perplexity-User.
Die praktische Konsequenz: Wer GPTBot blockiert, verhindert Training — behält aber die Sichtbarkeit in ChatGPT Search, solange OAI-SearchBot erlaubt ist. Das ist kein Widerspruch, sondern eine bewusste Trennung, die OpenAI dokumentiert anbietet. Generative Engine Optimization funktioniert nur dann, wenn die Such-Crawler auch tatsächlich crawlen dürfen.
Die 14 relevanten KI-Bots: User-Agent-Strings, Typ und Compliance
Die folgende Tabelle listet alle 14 Bots auf, die in Schweizer Logfiles regelmässig auftauchen oder für die GEO-Sichtbarkeit relevant sind. Der User-Agent-String ist exakt so zu verwenden, wie er in der dritten Spalte steht — inklusive Gross- und Kleinschreibung. Bots ohne eigenen Block erben die Regeln von User-agent: *.
| # | Bot | Betreiber | User-Agent (robots.txt) | Typ | robots.txt | GEO |
|---|---|---|---|---|---|---|
| 1 | OAI-SearchBot | OpenAI | OAI-SearchBot | Search | ✓ Ja | Sehr hoch |
| 2 | ChatGPT-User | OpenAI | ChatGPT-User | User-Action | ⚠ Teilweise | Sehr hoch |
| 3 | GPTBot | OpenAI | GPTBot | Training | ✓ Ja | Hoch* |
| 4 | PerplexityBot | Perplexity | PerplexityBot | Search | ✓ Ja | Sehr hoch |
| 5 | Perplexity-User | Perplexity | Perplexity-User | User-Action | ✗ Nein¹ | Hoch |
| 6 | Claude-User | Anthropic | Claude-User | User-Action | ✓ Ja | Hoch |
| 7 | ClaudeBot | Anthropic | ClaudeBot | Training | ✓ Ja | Mittel |
| 8 | DuckAssistBot | DuckDuckGo | DuckAssistBot | Search | ✓ Ja | Mittel |
| 9 | Google-Extended | Google-Extended | Training | ✓ Ja | Mittel² | |
| 10 | Applebot-Extended | Apple | Applebot-Extended | Training | ✓ Ja | Mittel³ |
| 11 | CCBot | Common Crawl | CCBot | Training | ✓ Ja | Niedrig |
| 12 | Bytespider | ByteDance | Bytespider | Training | ✗ Nein⁴ | Niedrig |
| 13 | Meta-ExternalAgent | Meta | meta-externalagent | Training | ✓ Ja | Niedrig |
| 14 | Amazonbot | Amazon | Amazonbot | Training | ✓ Ja | Niedrig |
¹ Perplexity-User gilt laut Perplexity als «Agent, kein Bot» — robots.txt ist nicht zwingend zu respektieren.
² Google-Extended steuert nur Gemini-Training, nicht Google Search oder AI Overviews.
³ Applebot-Extended steuert Apple Intelligence; mit Apple-Silicon-Verbreitung steigt die GEO-Relevanz.
⁴ Bytespider (ByteDance) wurde von Cloudflare und unabhängigen Analysen mit Non-Compliance dokumentiert.
* GPTBot steuert Training; OAI-SearchBot ist der separate Such-Indexer — beide unabhängig konfigurierbar.
Crawl-Aktivität in der Praxis: Was Logfiles bei Schweizer Websites zeigen
Aus Logfile-Auswertungen bei Schweizer Kundensites (Q1 2026, 50–500 Seiten, gemischte Branchen) zeigt sich ein klares Muster: GPTBot und ClaudeBot dominieren nach Seitenanzahl. Bytespider erscheint jedoch auch bei Domains, die einen Disallow: /-Eintrag für diesen User-Agent tragen — ein direktes Indiz für Non-Compliance. ClaudeBot hat zwischen Q3 2025 und Q1 2026 seine Crawl-Rate bei den beobachteten Sites etwa verdoppelt, was Branchenberichten über eine deutliche Skalierung von Anthropics Retrieval-Infrastruktur entspricht.
Rot = Bytespider, erschien auf Domains trotz explizitem Disallow: /. Grün = Such-Crawler. Blau = Training-Crawler.
CCBot (Common Crawl) taucht in einem anderen Muster auf: nicht täglich, sondern in Bursts von 200 bis 400 Seiten über wenige Tage, dann Wochen Pause. Wer CCBot blockiert, reduziert die Präsenz in Trainingsdaten-Pools, aus denen viele KI-Anbieter ihre Modelle aufbauen — ein Aspekt, der für Content-intensive Schweizer KMU relevant sein kann.
Entscheidungs-Matrix: Welcher Ansatz passt zu welchem Schweizer Geschäftstyp?
Es gibt keine universell richtige Antwort. Die richtige Frage ist: Was hat das Unternehmen zu verlieren — und was zu gewinnen? Die folgende Matrix ordnet die drei Bot-Kategorien den häufigsten Schweizer Geschäftstypen zu. Grün = erlauben, Rot = blockieren, Orange = Einzelfallentscheidung.
| Geschäftstyp | Training-Bots | Such-Bots | User-Action | Vorlage |
|---|---|---|---|---|
| Lokales KMURestaurant, Coiffeur, Handwerk | ✓ ErlaubenZitierbarkeit = Geschäft | ✓ Erlauben | ✓ Erlauben | Vorlage 1 |
| IT / Agentur / BeratungOhne proprietären Kerninhalt | ✓ Erlauben | ✓ Erlauben | ✓ Erlauben | Vorlage 1 |
| Treuhand / SteuerberatungFach-Know-how, Beratungsexpertise | ⚠ AbwägenExpertise schützen vs. Zitierbarkeit | ✓ Erlauben | ✓ Erlauben | Vorlage 2 |
| Arztpraxis / ZahnarztGesundheitliche Inhalte, DSG-Kontext | ⚠ AbwägenSensible Inhalte | ✓ Erlauben | ✓ Erlauben | Vorlage 2 |
| Anwaltskanzlei / NotariatFachinhalt schützen | ✗ Blockieren | ✓ Erlauben | ✓ Erlauben | Vorlage 3 |
| E-Commerce / OnlineshopPreise, Sortiment, Kundendaten | ✗ Blockieren | ✓ Erlauben | ⚠ SelektivCheckout/Account sperren | Vorlage 3 |
| SaaS / Paid ContentProprietäres IP, geschützte Bereiche | ✗ Blockieren | ⚠ SelektivNur Marketing-Seiten | ✗ BlockierenApp/API/Members | Vorlage 4 |
Das Schweizerische Datenschutzgesetz (DSG, rev. 1.9.2023) stellt keine direkten Anforderungen daran, welche Bots eine öffentliche Website crawlen dürfen. Wohl aber können robots.txt-Disallow-Direktiven für Training-Bots als technisches Opt-out dokumentiert werden — analog zum EU-Modell nach DSM Art. 4 (EU 2019/790). Für Schweizer Anwaltskanzleien oder Unternehmen, die auch EU-Kunden bedienen, kann diese Dokumentation rechtlich relevant sein.
Wenn robots.txt nicht reicht: Bytespider, Perplexity und die Server-Ebene
robots.txt ist eine höfliche Bitte, kein technischer Mechanismus. Für konforme Bots — OpenAI, Anthropic, Google, Apple, Amazon, DuckDuckGo — funktioniert sie zuverlässig. Für Bytespider und die Stealth-Crawler von Perplexity nicht. Cloudflare hat am 4. August 2025 eine Analyse veröffentlicht, die zeigt, wie Perplexity-Crawler User-Agents, IPs und ASNs rotieren, um Crawl-Beschränkungen zu umgehen. Das Fazit: robots.txt ist bei Perplexity keine verlässliche Verteidigungslinie.
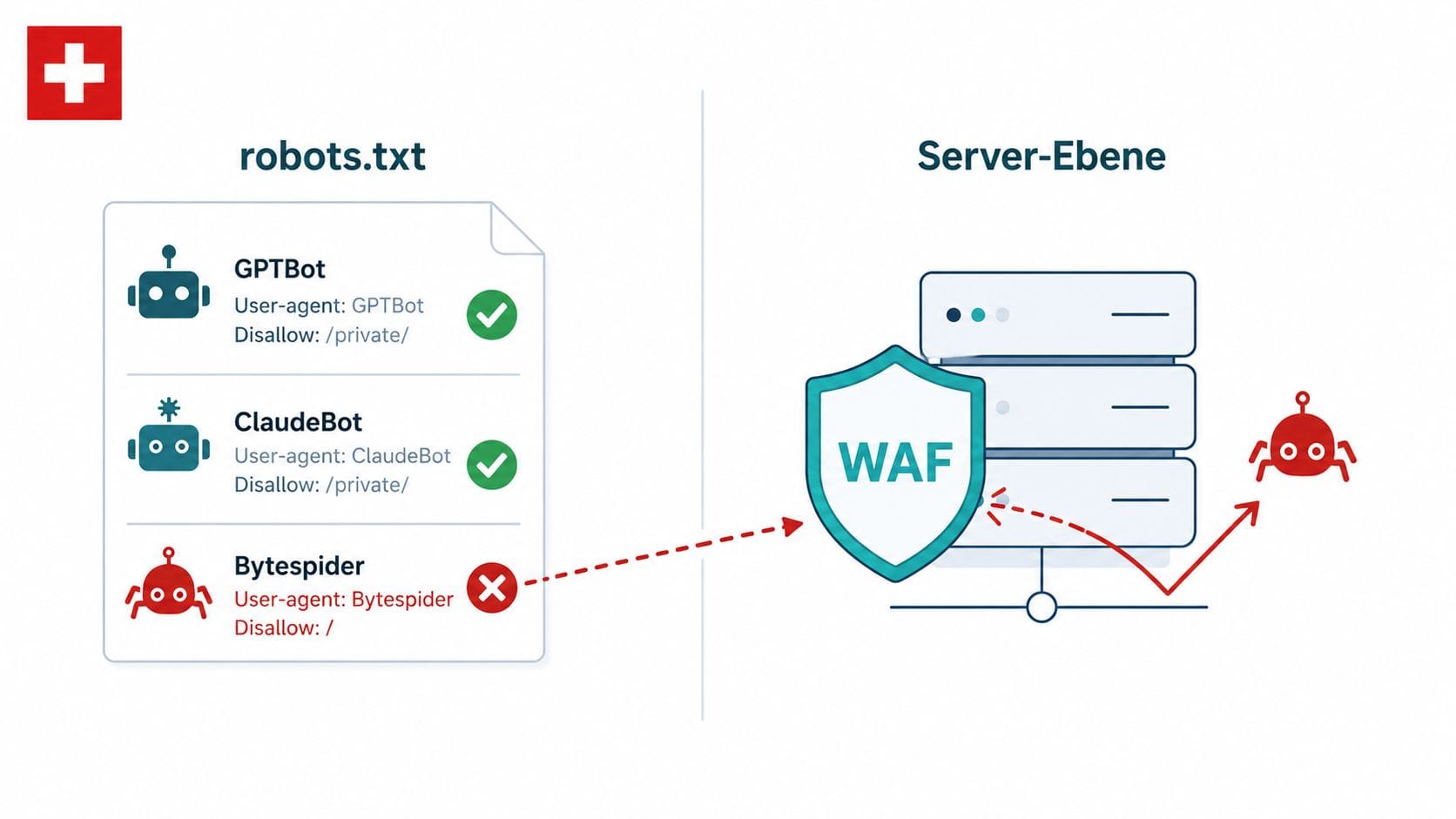
Für Schweizer KMU-Websites mit WordPress-Hosting gibt es drei praxisnahe Optionen. Cloudflare Free bietet seit August 2025 die «AI Crawl Control»-Funktion, mit der je Bot Allow, Block oder Charge eingestellt werden kann — auch auf Free-Accounts. .htaccess-Regeln blockieren bekannte User-Agent-Strings auf Apache-Servern zuverlässig, auch wenn der Bot die robots.txt ignoriert. nginx rate limiting schützt gegen aggressive Crawl-Bursts pro User-Agent. OAI-SearchBot, PerplexityBot und ClaudeBot sollten dabei niemals pauschal geblockt werden — das wäre das Äquivalent zu «Googlebot sperren» und eliminiert die KI-Sichtbarkeit vollständig. Mehr dazu, wie Googlebot und KI-Such-Crawler Seiten verarbeiten, erklärt der Beitrag zur Google-Indexierung.
Vier fertige robots.txt-Vorlagen für Schweizer Websites
Alle vier Vorlagen blockieren Bytespider — als einzigen Bot, für den die robots.txt-Direktive nicht zuverlässig greift, dokumentiert sie zumindest den Willen zum Opt-out. Jede Vorlage ist als vollständige robots.txt-Datei gedacht und muss im Website-Root unter /robots.txt erreichbar sein. Hinweis zur Reihenfolge: User-agent: * gilt als Catch-all für alle Bots ohne eigenen Block. Wer einen spezifischen Bot öffnen will, muss ihn in einem eigenen Block mit Allow explizit freischalten.
# robots.txt Vorlage 1: Offen — seo-partner.ch # Alle KI-Bots erlaubt; nur nicht-konforme und interne Bereiche blockiert User-agent: * Disallow: /wp-admin/ Disallow: /wp-login.php Disallow: /cart/ Disallow: /checkout/ Disallow: /account/ Disallow: /private/ Allow: / # Bytespider (ByteDance) — non-compliant, explizit sperren User-agent: Bytespider Disallow: / Sitemap: https://www.ihrewebsite.ch/sitemap.xml
# robots.txt Vorlage 2: Selektiv — seo-partner.ch # Training-Bots gesperrt; Such-Crawler offen für GEO-Sichtbarkeit User-agent: * Disallow: /wp-admin/ Disallow: /wp-login.php Disallow: /account/ Disallow: /private/ Allow: / # Alle Training-Crawler blockieren User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Google-Extended Disallow: / User-agent: CCBot Disallow: / User-agent: Applebot-Extended Disallow: / User-agent: Meta-ExternalAgent Disallow: / User-agent: Amazonbot Disallow: / User-agent: Bytespider Disallow: / # Such-Crawler explizit erlauben (GEO-Sichtbarkeit erhalten) User-agent: OAI-SearchBot Allow: / User-agent: PerplexityBot Allow: / User-agent: DuckAssistBot Allow: / Sitemap: https://www.ihrewebsite.ch/sitemap.xml
# robots.txt Vorlage 3: GEO-Fokus — seo-partner.ch # Training blockiert; Such-Bots nur auf öffentliche Bereiche User-agent: * Disallow: /wp-admin/ Disallow: /checkout/ Disallow: /cart/ Disallow: /account/ Disallow: /members/ Disallow: /api/ Allow: / # Alle Training-Crawler blockieren User-agent: GPTBot User-agent: ClaudeBot User-agent: Google-Extended User-agent: CCBot User-agent: Applebot-Extended User-agent: Meta-ExternalAgent User-agent: Amazonbot User-agent: Bytespider Disallow: / # OAI-SearchBot: öffentliche Seiten ja, transaktionale nein User-agent: OAI-SearchBot Disallow: /checkout/ Disallow: /cart/ Disallow: /account/ Allow: / User-agent: PerplexityBot Disallow: /checkout/ Disallow: /account/ Allow: / Sitemap: https://www.ihrewebsite.ch/sitemap.xml
# robots.txt Vorlage 4: Maximaler Schutz — seo-partner.ch # Alles gesperrt; nur SEO- und KI-Such-Bots explizit auf Marketing-Seiten geöffnet # Standard: alles sperren User-agent: * Disallow: / # Googlebot und Bingbot: voller Zugriff (SEO-Grundlage) User-agent: Googlebot Allow: / Disallow: /app/ Disallow: /admin/ Disallow: /api/ Disallow: /members/ User-agent: bingbot Allow: / Disallow: /app/ Disallow: /admin/ Disallow: /api/ Disallow: /members/ # KI-Such-Bots: nur Marketing-Seiten und Blog User-agent: OAI-SearchBot Allow: /blog/ Allow: /ueber-uns/ Allow: /leistungen/ Disallow: / User-agent: PerplexityBot Allow: /blog/ Allow: /leistungen/ Disallow: / Sitemap: https://www.ihrewebsite.ch/sitemap.xml
Wer seinen aktuellen KI-Crawler-Status analysieren lassen möchte — welche Bots aktuell crawlen, ob Bytespider trotz Disallow in den Logs auftaucht — kann eine kostenlose SEO-Analyse anfragen. Weiterführende technische Grundlagen zu Crawling und Indexierung finden sich im Technisches-SEO-Bereich.
Training-Bots: 88% → 72% · Such-Bots: 11% → 17% · User-Action-Bots: 1% → 11% (11-faches Wachstum)
Häufige Fragen zu robots.txt und KI-Crawlern
Wenn ich GPTBot blockiere, verliere ich dann die ChatGPT-Sichtbarkeit?
Schadet das Blockieren von Google-Extended dem Google-Ranking?
Wie zuverlässig ist robots.txt als Schutz gegen KI-Crawler?
.htaccess — die einzig verlässliche Kontrolle. robots.txt bleibt trotzdem sinnvoll: Als Dokumentation des Willen zum Opt-out hat sie auch rechtliche Relevanz.Was bedeutet «User-Agent: *» in Kombination mit KI-Bot-Regeln?
User-agent: * ist der Catch-all-Block und gilt für jeden Bot ohne eigenen Block. Wenn User-agent: * mit Disallow: / gesetzt ist, sind alle Bots ohne eigenen Block gesperrt — auch OAI-SearchBot, wenn dieser keinen eigenen Allow-Block hat. Das ist der häufigste Konfigurationsfehler. Wer Vorlage 4 (maximaler Schutz) nutzt, muss alle gewünschten Bots danach explizit mit eigenem Block und Allow: / freischalten. Ohne diesen expliziten Block würde der *-Block greifen.Wie prüfe ich, welche KI-Bots meine Website bereits crawlen?
GPTBot|OAI-SearchBot|ChatGPT-User|ClaudeBot|PerplexityBot|Google-Extended|CCBot|Bytespider|Meta-ExternalAgent|Applebot|Amazonbot|DuckAssistBot. Tools wie Screaming Frog Log Analyser, Botify oder OnCrawl verarbeiten diese Logs und visualisieren Bot-Verteilungen. Wer keinen Logfile-Zugang hat, kann über Cloudflare Analytics einen ersten Eindruck gewinnen — die Bot-Kategorie «AI Crawlers» wird dort seit 2025 separat ausgewiesen. Die Google Search Console zeigt KI-Bots nicht getrennt von anderen Crawlern.Zuletzt aktualisiert: Juni 2026. Die KI-Crawler-Landschaft verändert sich schnell — neue Bots kommen hinzu, User-Agent-Strings können sich ändern.
PerplexityBot ist einer der KI-Crawler, die eine explizite robots.txt-Entscheidung erfordern: PerplexityBot in der robots.txt: erlauben oder blockieren?.
OAI-SearchBot hat einen eigenen User-Agent, der in der robots.txt separat konfiguriert werden kann: OAI-SearchBot in der robots.txt: korrekte Konfiguration.