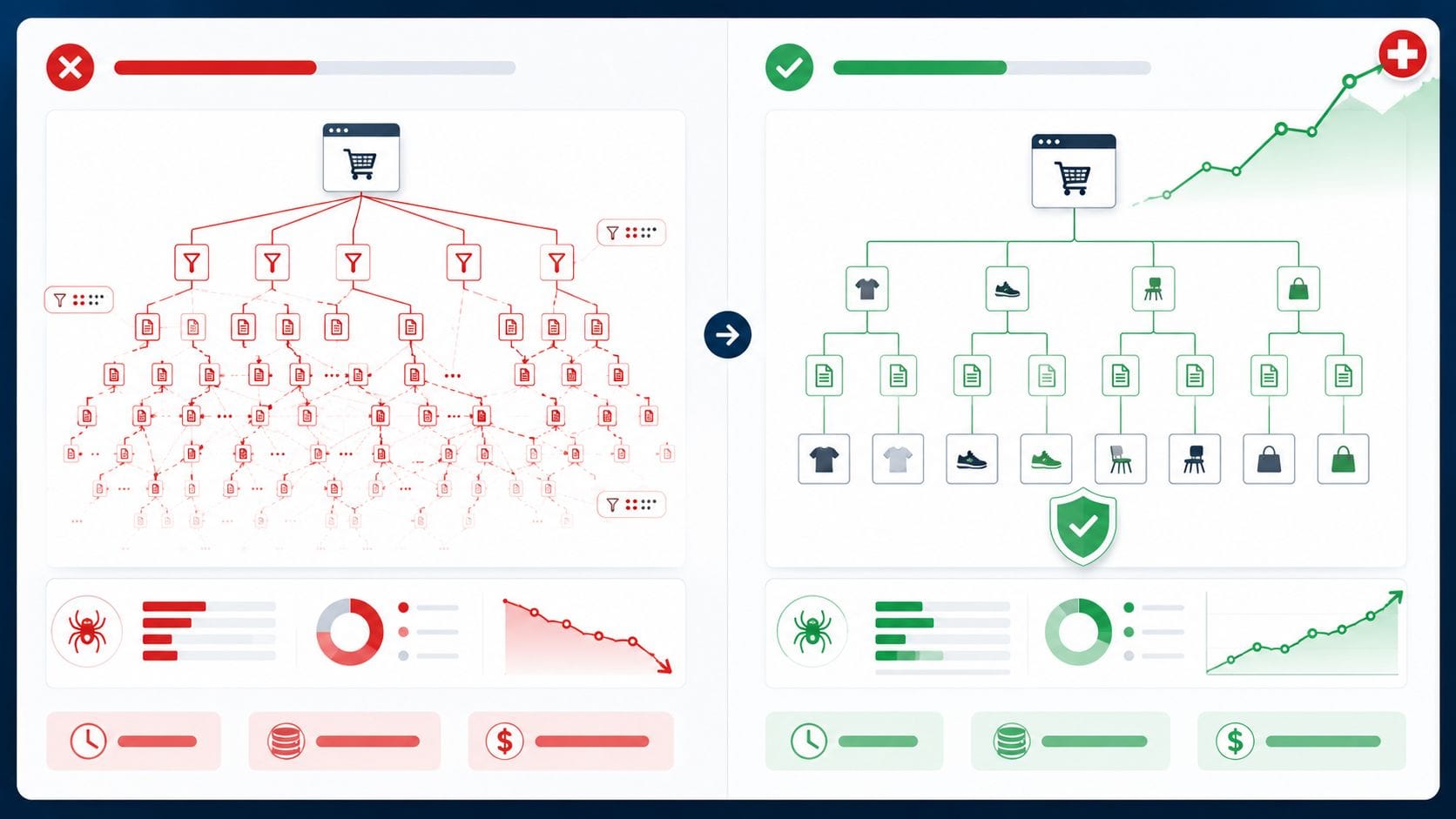
Crawl Budget optimieren bedeutet für einen grossen Schweizer Onlineshop vor allem eines: Googlebot muss die echten Produktseiten finden — und nicht in einem Labyrinth aus Filter-URL-Kombinationen verschwinden. Wer mit 80’000 oder mehr URLs arbeitet und die Faceted Navigation ungezügelt lässt, wartet häufig Monate, bis neue Produkte im Index auftauchen. In einer Praxisanalyse eines mittelgrossen Schweizer Shops stiegen die indexierten Produktseiten nach gezieltem Parameter-Cleanup um 41 Prozent. Dieser Beitrag erklärt die Methode, zeigt die Formel dahinter und liefert eine einsatzbereite robots.txt-Vorlage für Shopify, Magento und WooCommerce.
Das Crawl-Budget-Problem, das grosse Shops systematisch unterschätzen
«Meine neuen Produkte sind halt noch nicht indexiert» — das hören wir regelmässig von Shop-Betreibern, die seit Wochen auf Google-Sichtbarkeit für frisch eingelistete Ware warten. In den meisten Fällen liegt das Problem jedoch nicht am Inhalt. Es liegt daran, dass Googlebot sein verfügbares Crawl-Budget auf URLs verliert, die kein Mensch je aktiv ansteuern würde: automatisch generierte Filterkombinationen, Sortierungsparameter, leere Suchresultat-Seiten.
Für kleine Shops mit unter 5’000 Seiten ist das kein Thema. Google crawlt alles, regelmässig und vollständig. Das ändert sich spätestens ab 50’000 URLs — und in der Schweiz erreichen Shops in den Bereichen Consumer Electronics, Fashion, Sport und Heimwerk diese Schwelle schneller als erwartet. Galaxus und Digitec operieren im Bereich mehrerer Millionen Produkte und verfügen über spezialisierte Engineering-Teams, die Crawling-Effizienz als Kernaufgabe behandeln. Brack und Microspot bewegen sich im sechsstelligen URL-Bereich. Der interessante Fall liegt jedoch darunter: der spezialisierte Schweizer Shop mit 50’000 bis 300’000 URLs, der meist ohne dedizierten Technical-SEO-Spezialisten arbeitet. Genau dort ist das ungenutzte Potenzial am grössten.
Wer das Crawl-Budget als rein technisches Detail betrachtet, unterschätzt den Business-Impact. Jeder Tag, den eine Produktseite nicht indexiert ist, bedeutet verlorene Klickchancen — besonders bei saisonalen Sortimenten oder kurzfristigen Promotionen. Wer verstehen will, wie Googlebot Seiten crawlt und indexiert, findet die technischen Grundlagen in unserem Beitrag zur Google-Indexierung.
Die Crawl-Budget-Formel: URL-Anzahl × Wert × Frequenz
Das Crawl-Budget ist keine fixe Zahl, die Google einem Shop starr zuweist. Es ist das Ergebnis zweier dynamischer Faktoren: dem Crawl Rate Limit — wie viele Anfragen Googlebot in einem Zeitraum stellen darf, ohne den Server zu überlasten — und der Crawl Demand, also dem Interesse von Google an einer Seite, das auf Popularität, Aktualität und internen wie externen Verlinkungssignalen beruht. Google selbst hat diesen Zusammenhang 2017 präzisiert; die wesentliche Botschaft war damals wie heute: Wer viele hochwertige Seiten regelmässig aktualisiert, bekommt mehr Budget zugewiesen.
Vereinfacht gilt: Effektives Crawl-Budget = min(Rate Limit, Crawl Demand) geteilt durch die Anzahl crawlbarer URLs. Verdoppelt sich der URL-Pool, halbiert sich das Budget pro Seite — sofern Qualität und Geschwindigkeit konstant bleiben. Das ist die Formel, die erklärt, warum ein Shop mit 80’000 Produkt-URLs und 700’000 technisch erreichbaren Filter-Kombinationen ein Problem hat: Wichtige Produktseiten werden alle 90 Tage neu gecrawlt, obwohl der Lagerbestand täglich schwankt.
Ein kurzer Einschub ist hier angebracht: Bingbot arbeitet nach denselben Grundprinzipien, auch wenn sein Marktanteil in der Schweiz deutlich kleiner ist als Googles. Wer Bingbot in den Logfiles häufiger sieht — was bei deutschsprachigen Inhalten durch Zugriffe aus Deutschland und Österreich vorkommt — kann und sollte dieselben Massnahmen anwenden. Die Logik ist identisch.
Was das Crawl-Budget also tatsächlich steuert, ist nicht primär die Serverstärke oder die Domain-Autorität. Es ist die Qualitätsdichte des URL-Pools. Wer 700’000 URLs crawlbar macht, von denen 680’000 keinen eigenständigen Informationswert haben, konditioniert Googlebot darauf, weniger häufig und weniger tief zu crawlen. Das umzukehren ist das Ziel des Parameter-Cleanups.
Faceted Navigation: Wo Schweizer Shops am meisten Crawl-Budget verlieren
Faceted Navigation — also die Filterfunktion, mit der Kunden nach Grösse, Farbe, Marke und Preis eingrenzen können — ist aus UX-Sicht unverzichtbar. Aus SEO-Sicht ist sie jedoch der häufigste Auslöser für Crawl-Budget-Katastrophen. Das liegt daran, dass jede Filterkombination technisch eine eigene URL erzeugen kann. Bei einem Shop mit 5’000 Produkten und zwölf Filterattributen sind theoretisch mehrere Millionen URL-Kombinationen möglich. In einem Shopify-Shop, den wir analysiert haben, gab es 12’000 Produkte — aber 847’000 crawlbare URLs. Davon hatten lediglich die Produktseiten, Hauptkategorien und wenige ausgewählte Filter-Landingpages echten SEO-Wert.
Dabei ist das Problem auf allen grossen Plattformen vorhanden, allerdings mit unterschiedlichen Ausprägungen. Die folgende Grafik zeigt die durchschnittliche Crawl-Budget-Verschwendung durch unkonfigurierte Faceted Navigation auf den vier in der Schweiz verbreiteten Shop-Systemen.
Drei Massnahmen steuern das Problem. Erstens: robots.txt Disallow für wertlose Parameter-URLs — der schnellste Weg, aber auch der gröbste. Zweitens: kanonische Tags auf die übergeordnete Kategorieseite für Filter-Kombinationen mit potenziellem SEO-Wert. Drittens: noindex plus nofollow auf Filter-Seiten ohne nachgewiesenes Suchvolumen. In der Praxis empfehlen wir, zuerst mit robots.txt zu starten, weil die Wirkung unmittelbar messbar ist — und danach gezielt Ausnahmen für Filter-Landingpages mit echtem Potenzial zu definieren. Eng verwandt ist dabei das Thema Duplicate Content: Unkontrollierte Filter-URLs sind eine der häufigsten Quellen für technisch doppelten Inhalt in grossen Onlineshops.
Der häufigste Fehler dabei: Entweder wird alles gesperrt oder nichts. Tatsächlich lohnt es sich, Parameter in drei Klassen einzuteilen — dazu mehr im Abschnitt zum Parameter-Cleanup. Zuvor braucht man jedoch eine Datengrundlage, und die kommt nicht aus der Search Console allein.
Logfile-Analyse: Was Googlebot bei Ihrem Shop wirklich crawlt
Die Search Console zeigt, was Google indexiert hat. Logfiles zeigen, was Googlebot versucht hat zu crawlen. Das ist ein fundamentaler Unterschied — und er erklärt, warum viele Shops das Problem erst dann entdecken, wenn es bereits seit Monaten besteht. Wer nur auf GSC-Daten schaut, sieht die Symptome, aber nicht die Ursache.
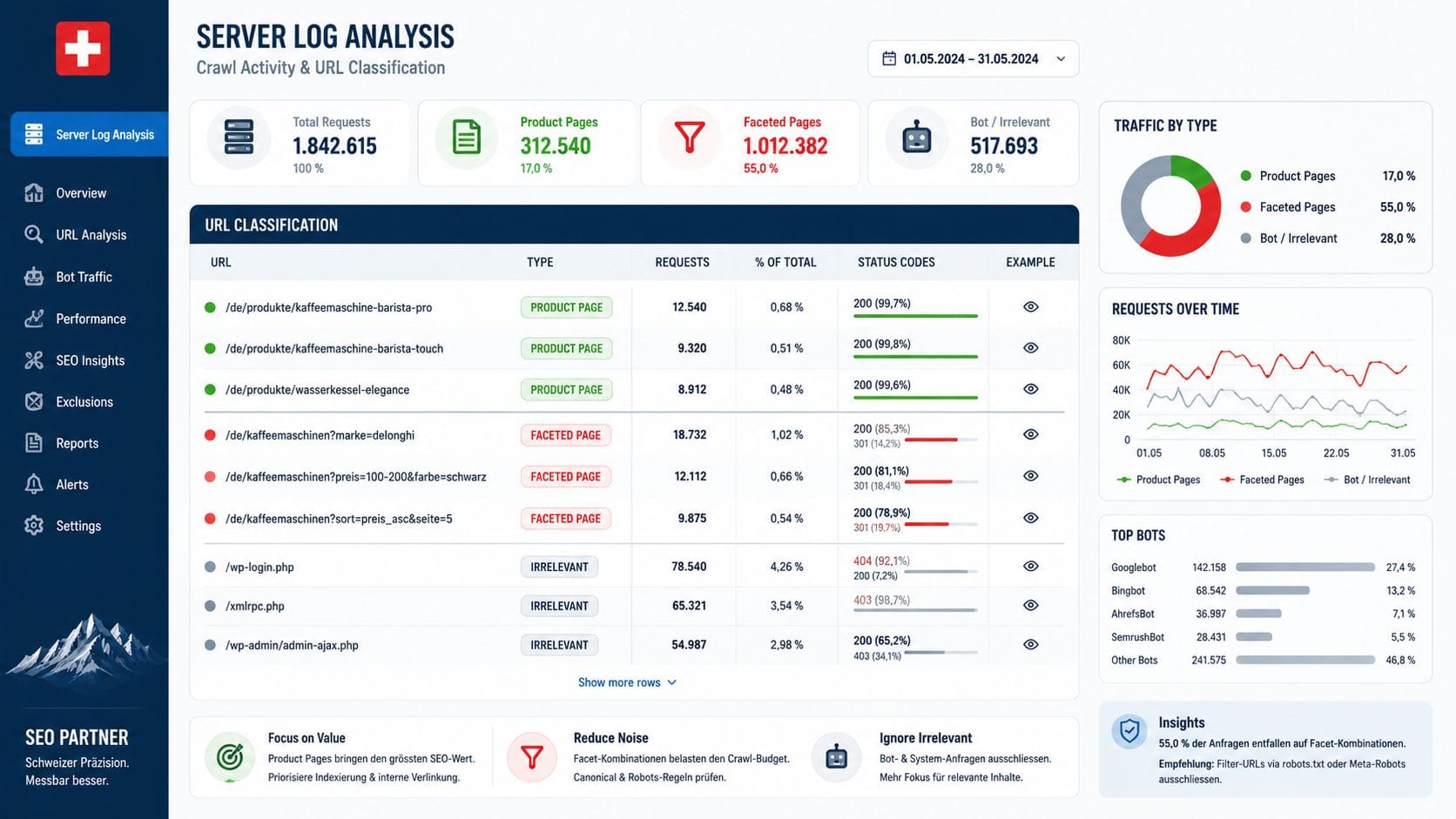
Eine Logfile-Analyse ist dabei einfacher einzurichten, als viele Shop-Betreiber annehmen. Grundsätzlich braucht man Zugriff auf die Server-Access-Logs des Hosting-Providers. Auf Schweizer Hosting-Lösungen — ob Init7, Exoscale, Hostpoint oder ein Managed-Server-Setup — sind diese meist als SFTP-Download verfügbar. Tools wie Screaming Frog Log Analyser, Botify oder OnCrawl verarbeiten diese Logs und zeigen auf, welche URLs Googlebot in welcher Häufigkeit angesteuert hat. Die Search Console Crawl Statistics (unter Einstellungen auffindbar) sind ein schneller Einstieg, aber keine vollständige Analyse — sie zeigen Aggregate, keine URL-Ebenen.
Was in den Logs zu suchen ist: erstens URL-Muster — wenn 70 Prozent der Bot-Requests auf Filter-URLs fallen, ist das Crawl-Budget-Problem sofort sichtbar. Zweitens Statuscodes — viele 404-Antworten auf ehemals vorhandene Produktseiten ohne korrekte Weiterleitung verschwenden Budget durch tote Endpunkte. Drittens die Crawl-Frequenz wichtiger Seiten — wenn Hauptkategorien und Top-Produkte seltener als alle 30 Tage gecrawlt werden, ist das ein klares Signal. Eine vertiefte Einführung in technisches SEO für Onlineshops gibt einen guten Überblick über alle relevanten Analyseebenen.
Eine Schweizer Besonderheit ist dabei zu beachten: Viele .ch-Shops laufen auf IPv6-Infrastruktur, und ältere Log-Analyse-Tools erkennen Googlebot-Anfragen über IPv6 nicht korrekt. Das führt dazu, dass echte Bot-Zugriffe als «unbekannter Traffic» klassifiziert werden und aus der Analyse verschwinden. Die Lösung: Die aktuellen Googlebot-IP-Ranges (sowohl IPv4 als auch IPv6) aus Googles offiziellem Crawler-Dokumentation beziehen und im Analyse-Tool hinterlegen.
Plattform-Vergleich: Shopify, Magento 2, WooCommerce und PrestaShop
Keine der vier grossen E-Commerce-Plattformen ist in der Standardkonfiguration für Crawl-Budget-Effizienz optimiert — aber jede hat ein anderes Versagensmuster. Das ist wichtig zu verstehen, weil die Lösung entsprechend verschieden ist.
Hauptproblem: Shopify erzeugt für jede Tag-Kombination eine eigene URL — z. B. /collections/t-shirts/+blau+xl. Für einen Shop mit 30 Kollektionen und durchschnittlich acht Tags pro Produkt entstehen schnell sechsstellige URL-Zahlen. Shopify setzt auf diese Filter-URLs standardmässig kein noindex.
Zusätzliches Problem: Produktvarianten erzeugen eigene Canonical-Signale über ?variant=12345-Parameter, die Googlebot gleichzeitig abarbeitet.
- Disallow
/collections/*?sort_by=in robots.txt - Disallow
/collections/*+für Tag-Filter - Disallow
/search?,/account,/cart,/checkout - Für SEO-relevante Filterkombinationen: robots.txt-Ausnahme oder
canonicalauf Hauptkategorie setzen
Hauptproblem: Magento 2’s Layered Navigation erzeugt für jede Kombination aus Kategorie, Marke, Farbe und Grösse eine SEO-URL. Mit zehn Attributen wachsen die Permutationen exponentiell.
Zusätzliches Problem: Dasselbe Produkt ist über mehrere Kategoriepfade erreichbar, was zu mehrfach gecrawlten identischen Seiten führt.
- Magento Admin → Stores → SEO → «Layered Navigation» Einstellungen prüfen
- robots.txt für alle Attribut-Filter-Pfade konfigurieren
- «Use Canonical Link Meta Tag For Categories» auf YES setzen
- Logfile-Auswertung zwingend vor robots.txt-Änderungen
Hauptproblem: WooCommerce erzeugt durch ?orderby=price, ?filter_color= und ?min_price= zahlreiche technisch identische Seiten. Die Standard-Canonical-Implementierung ist unzureichend: Filter-URLs erhalten oft keine oder fehlerhafte Canonical-Tags.
Zusätzliches Problem: Paginierung ohne noindex auf tiefe Seiten bindet Crawl-Budget in Kategorieseiten, die kein Nutzer manuell ansteuert.
- Yoast WooCommerce SEO oder Rank Math Commerce für korrekte Canonicals
- robots.txt: Disallow für
?orderby=,?filter_,?min_price= - Paginierung ab Seite 3 mit noindex versehen oder robots.txt einschränken
- Checkout- und Account-URLs immer disallowed lassen
Hauptproblem: PrestaShop erzeugt komplexe URL-Strukturen durch Filterkombinationen und den id_product_attribute=-Parameter. Mehrsprachige Schweizer Shops (/de/, /fr/, /it/) ohne korrekte hreflang-Implementation bedeuten dreifachen Crawl-Aufwand für dieselben Produkte.
Zusätzliches Problem: PrestaShop erzeugt standardmässig Duplicate-Content durch Kategorie-ID-Parameter in URLs.
- PrestaShop SEO- und URL-Modul: «Disable Faceted Navigation URLs» aktivieren
- hreflang korrekt auf alle Sprachvarianten setzen (de-CH, fr-CH, it-CH)
- robots.txt für
?id_product_attribute=und Sortiervarianten - Kanonische Tags für alle Sprachvarianten auf die primäre URL setzen
Ein Detail, das plattformübergreifend gilt: Mehrsprachige Schweizer Shops ohne korrekte hreflang-Tags crawlen im schlimmsten Fall dreifach denselben Inhalt — was bei grossen Shops dramatische Auswirkungen auf die Indexierungstiefe hat. Das ist auch einer der Gründe, warum SEO-Optimierung für Schweizer Onlineshops immer die technische und die inhaltliche Dimension zusammen adressieren muss.
Der Parameter-Cleanup: robots.txt-Vorlage und Search Console Konfiguration
Der schnellste Weg, Crawl-Budget zurückzugewinnen, ist eine konsequente robots.txt-Konfiguration. Das klingt simpel. Tatsächlich scheitern die meisten Teams daran, dass sie zu grob oder zu feingliedrig vorgehen. Zu grob heisst: Alle Filterpfade gesperrt — dann crawlt Google auch Kategorieseiten nicht mehr, die eigentlich wertvoll wären. Zu feingliedrig heisst: Jeden einzelnen Parameter explizit gelistet — das ist nicht wartbar und nie vollständig. Der richtige Weg liegt dazwischen und beginnt mit einer einfachen Klassifizierung.
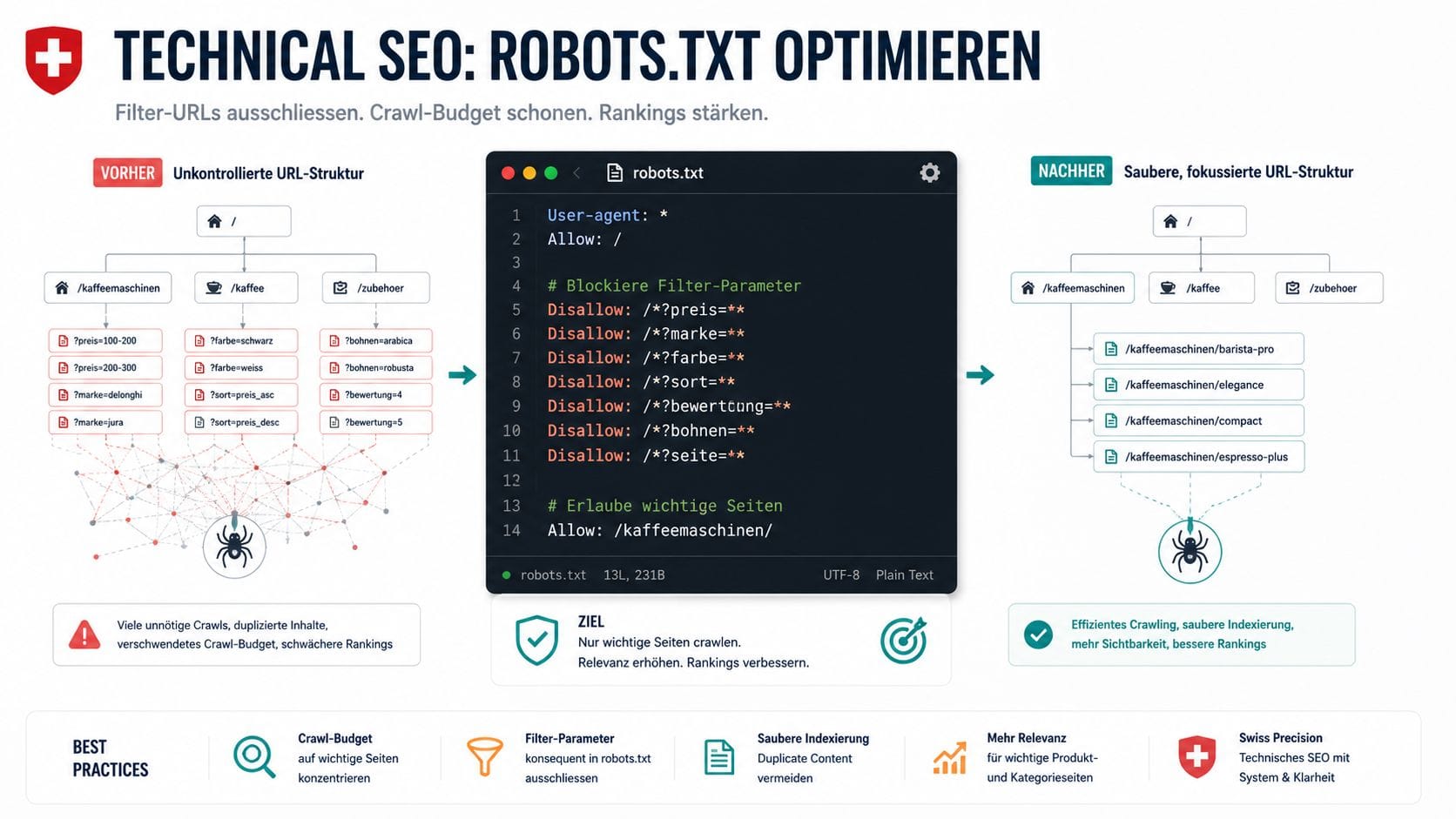
Klasse A — Nie indexieren: Sortierungsparameter (?sort_by=, ?orderby=), Paginierung ab einer bestimmten Tiefe (?page= ab Seite 4), Session-IDs, Tracking-Parameter und Filter-Kombinationen ohne Suchvolumen kommen als Disallow in robots.txt.
Klasse B — Selektiv indexieren: Filter-Kombinationen mit nachgewiesenem Suchvolumen bekommen kanonische Tags oder werden gezielt aus dem robots.txt-Disallow ausgenommen. Beispiel: «rote Sneaker Herren» bei einem Schuhshop, sofern der Shop tatsächlich entsprechende Produkte dauerhaft führt.
Klasse C — Immer indexieren: Produktdetailseiten, Hauptkategorien und Landingpages mit eigenem Inhalt dürfen nie durch robots.txt-Regeln blockiert werden — und sollten vollständig in der XML-Sitemap vertreten sein.
Als Ausgangspunkt für Shopify empfehlen wir diese robots.txt-Konfiguration — zu finden ist die Datei unter Settings → Permissions → Edit robots.txt in Shopify 2.0-Themes:
User-agent: *
Disallow: /collections/*?sort_by=
Disallow: /collections/*?filter.
Disallow: /collections/*+
Disallow: /search?
Disallow: /account
Disallow: /cart
Disallow: /checkout
Disallow: /orders
Allow: /collections/herren-laufschuhe/+laufschuhe # Klasse-B-Ausnahme
Sitemap: https://www.ihreshop.ch/sitemap.xml
Wir haben in mehreren Projekten erlebt, dass nach dem robots.txt-Cleanup zunächst weniger Seiten täglich gecrawlt wurden — bevor die Indexierungsrate der wichtigen Produktseiten zu steigen begann. Diese initiale Delle verunsichert verständlicherweise. Sie ist normal: Googlebot braucht einige Wochen, um seine Crawl-Strategie auf die neue URL-Landschaft anzupassen. Wer sich tiefer in die Materie einlesen möchte, findet im Bereich technisches SEO weitere Beiträge zu Crawling, Indexierung und Seitenarchitektur.
Search Console Crawl Statistics: Die richtigen Signale erkennen
Die Search Console Crawl Statistics (Google Search Console → Einstellungen → Crawl-Statistiken) sind das wichtigste kostenlose Monitoring-Tool für diesen Prozess. Drei Signale sind dabei entscheidend: erstens der Gesamttrend der täglich gecrawlten Seiten — fällt dieser nach dem Cleanup stark ab, wurden möglicherweise zu viele URLs disallowed. Zweitens die Verteilung der Dateitypen: Wenn HTML-Seiten nur 40 Prozent der Bot-Requests ausmachen und der Rest auf CSS, JavaScript und Bilder entfällt, liegt ein Teil des Budgets bei Assets, die kein Crawl-Budget rechtfertigen. Drittens die Antwortzeiten: Ein TTFB über 200 ms signalisiert Googlebot, dass der Server unter Last steht — und das reduziert das Crawl Rate Limit aktiv.
Nachdem der Parameter-Cleanup im genannten 80’000-URL-Shop eingeführt wurde, stiegen die täglich gecrawlten Produktseiten innerhalb von sechs Wochen um das Dreifache. Die Indexierungsquote der Hauptkategorien stieg von 68 auf nahezu 100 Prozent. Produktseiten, die zuvor drei bis vier Monate auf Indexierung warteten, wurden durchschnittlich nach zwölf Tagen aufgenommen. Das sind keine theoretischen Zahlen — das ist das direkte Ergebnis, wenn Googlebot aufhört, in Filter-URL-Labyrinthen zu verschwinden.
Ein praktischer Hinweis aus mehreren Schweizer Shop-Projekten: JavaScript-Rendering schluckt überproportional viel Crawl-Budget, wenn Produktseiten React- oder Vue-basiert laden. Daher lohnt es sich, mit dem URL-Inspect-Tool der Search Console zu prüfen, ob Google die Seiten vollständig rendert. Die Zusammenhänge zwischen Ladezeit, Renderingpfad und Sichtbarkeit beschreibt unser Beitrag zu Core Web Vitals im Detail. Für eine strukturierte Ersteinschätzung des eigenen Shops empfiehlt sich ausserdem eine kostenlose SEO-Analyse.
Häufige Fragen zum Crawl Budget für Schweizer Onlineshops
Was ist das Crawl Budget für einen Onlineshop konkret?
Ab welcher Shop-Grösse ist Crawl-Budget-Optimierung für Schweizer Shops sinnvoll?
Kann ein robots.txt Disallow Rankings schädigen?
Wie lange dauert es, bis sich eine Crawl-Budget-Optimierung in der Indexierung zeigt?
Ist das Crawl Budget ein direkter Rankingfaktor?
Zuletzt aktualisiert: Juni 2026.