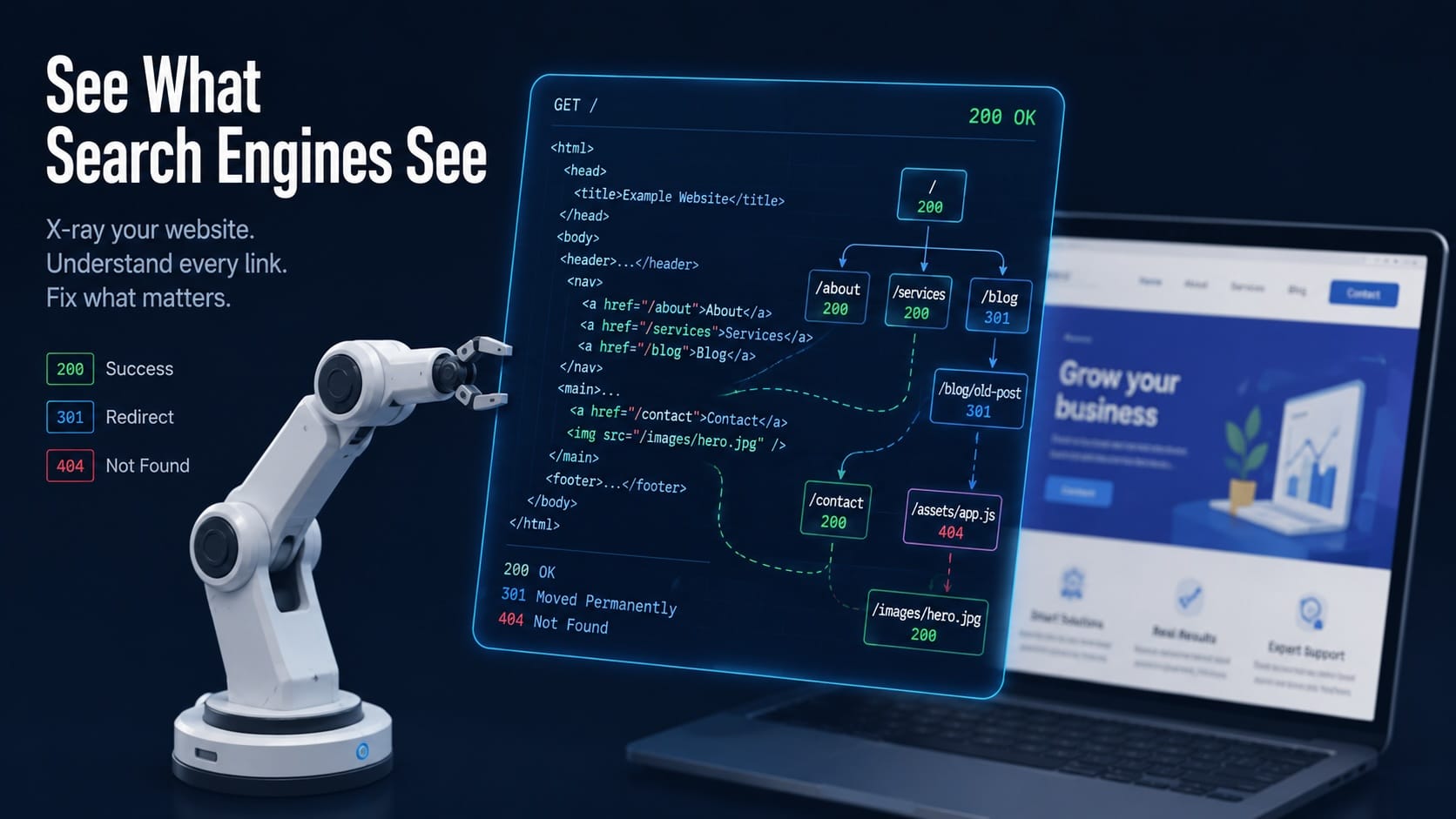
Was auf Ihrem Screen und in Googles Index zwei verschiedene Welten sind
Sie öffnen Ihre Website. Alles sieht gut aus — schnelle Ladezeit, hübsches Design, sorgfältig geschriebene Texte. Was Sie sehen, ist jedoch nicht das, was Google sieht. Googlebot liest keine fertig gerenderte Website wie ein Mensch. Er crawlt Rohdaten: HTML-Zeilen, HTTP-Antwortcodes, Verlinkungsstrukturen, Metadaten. Und manchmal — nicht immer — wartet er noch Sekunden, bis JavaScript fertig geladen hat, bevor er überhaupt entscheidet, ob er den Inhalt indexiert.
Diese Lücke zwischen dem, was Sie sehen, und dem, was Google liest, ist der Ursprung vieler unerklärlicher SEO-Probleme. Seiten, die trotz gutem Content nicht ranken. Shops, deren Produktseiten wochenlang unsichtbar bleiben. Websites, bei denen die wichtigsten Inhalte tief in JavaScript vergraben und für Googlebot faktisch unsichtbar sind.
Dieser Artikel erklärt, wie Google Indexierung, Crawling und das Crawl Budget wirklich funktionieren — und beleuchtet zwei Themen, die in anderen Ratgebern fehlen: was moderne KI-Crawler wie der OAI-SearchBot von OpenAI auf Ihrer Website suchen, und warum Schweizer E-Commerce-Shops eine ganz spezifische JavaScript-Falle kennen sollten.
Wie Google Ihre Website wirklich liest — die fünf Phasen
Die meisten Beschreibungen von Crawling und Google Indexierung vereinfachen stark: «Googlebot crawlt Ihre Seite und nimmt sie in den Index auf.» Das stimmt im Kern — überspringt aber das, was dazwischen passiert und wo die meisten Probleme entstehen. Tatsächlich durchläuft jede URL fünf separate Phasen, bevor sie in den Google-Suchergebnissen auftauchen kann. Und sie kann in jeder dieser Phasen scheitern.
Viele Websites scheitern bei der Google Indexierung bereits in Phase 2 oder 3 — ohne es zu wissen. Sie produzieren guten Content — aber Googlebot erreicht ihn nicht oder liest ihn falsch. Das Ranking-Problem ist dann kein Content-Problem, sondern ein technisches. Und die häufigste Quelle dieses Problems in der Praxis sind falsch konfigurierte robots.txt-Dateien, fehlende Sitemaps und JavaScript-lastige Frontends.

Robots.txt: Das Türsteher-Dokument, das niemand prüft
Die robots.txt-Datei liegt auf jeder Website unter ihredomain.ch/robots.txt. Sie enthält Anweisungen für Crawler: Welche Verzeichnisse dürfen betreten werden, welche nicht? Googlebot prüft diese Datei, bevor er eine URL crawlt. Wenn eine URL dort blockiert ist, crawlt Googlebot sie nicht — unabhängig davon, wie wichtig sie ist, wie viele Backlinks auf sie zeigen oder wie gut ihr Content ist. Sie existiert für Google schlicht nicht.
Das klingt banal — ist es aber nicht. In unserer Audit-Praxis finden wir bei Schweizer KMU-Websites regelmässig robots.txt-Fehler, die ganze Verzeichnisse oder sogar die gesamte Website blockieren. Meistens entstand das durch einen Relaunch, bei dem die Staging-Konfiguration versehentlich auf die Live-Website übertragen wurde. Der klassische Fall: Eine Website ist mit Disallow: / für alle Bots gesperrt — und der Inhaber weiss nichts davon, weil die Website im Browser perfekt lädt.
User-agent: *
Disallow: /wp-admin/
Disallow: /checkout/
Disallow: /cart/
Allow: /wp-admin/admin-ajax.php
# Sitemap deklarieren — hier wissen alle Bots, wo sie suchen sollen
Sitemap: https://ihredomain.ch/sitemap.xml
# OAI-SearchBot erlauben (für ChatGPT-Zitierbarkeit)
User-agent: OAI-SearchBot
Allow: /
# GPTBot blockieren (Trainingsdaten, falls unerwünscht)
User-agent: GPTBot
Disallow: /
# FALSCH: Das blockiert ALLES — inklusive Googlebot
User-agent: *
Disallow: /
# ↑ Dieser Fehler ist häufiger als man denkt
Ein Detail, das viele nicht wissen: Robots.txt blockiert das Crawling — aber nicht die Indexierung. Google kann eine gesperrte URL trotzdem in den Index aufnehmen, wenn externe Links auf sie zeigen. Die URL erscheint dann in den Suchergebnissen, aber ohne Snippet, ohne Titel, ohne Beschreibung. Das sieht aus wie ein kaputter Sucheintrag und kostet Klicks. Der Unterschied zwischen «nicht crawlbar» und «nicht indexierbar» ist daher wichtig — und genau hier spielen noindex-Tags eine andere Rolle als robots.txt-Anweisungen.
Sitemap XML: Mehr als eine Linkliste
Eine Sitemap XML-Datei ist nicht dafür da, Google zur Google Indexierung bestimmter Seiten zu zwingen. Das können Sie nicht. Was die Sitemap tut: Sie gibt Googlebot eine priorisierte Liste von URLs und informiert ihn über deren letztes Änderungsdatum. Das beschleunigt die Discovery neuer und aktualisierter Inhalte erheblich — besonders bei grossen Websites oder solchen, die regelmässig neue Seiten hinzufügen.
Dabei gilt eine Regel, die kontraintuitiv klingt: In einer Sitemap XML sollten ausschliesslich URLs stehen, die Sie auch wirklich indexiert haben möchten. Keine Weiterleitungen, keine 404-Fehlerseiten, keine noindex-Seiten, keine Parameter-URLs. Wer Fehler-URLs in die Sitemap aufnimmt, gibt Googlebot widersprüchliche Signale — und verschwendet Crawl-Budget. Genau das passiert beim Thema Crawl-Budget häufig ohne Absicht.
Für Schweizer Websites mit mehrsprachigem Inhalt gilt ausserdem: Hreflang-Annotierungen gehören in die Sitemap oder direkt ins HTML — nicht beides gleichzeitig, nicht unterschiedlich. Widersprüche zwischen Sitemap-Hreflang und HTML-Hreflang führen dazu, dass Google beide ignoriert und selbst entscheidet, welche Sprachversion welche Nutzer sieht. Das ist ein typisches Schweizer DE/FR/IT-Website-Problem, das wir regelmässig in Audits beheben. Mehr über technische SEO-Grundlagen finden Sie in unserem Glossar.
Crawl Budget: Wie Google Zeit auf Ihrer Website verteilt
Crawl Budget ist die Ressource, die Googlebot einer Domain insgesamt zuteilt — abhängig von Autorität, Servergeschwindigkeit und bisherigem Crawling-Verhalten. Grossen, starken Websites weist Google mehr Crawl-Budget zu als kleinen, neuen. Das führt zu einem praktischen Problem: Kleine Schweizer KMU-Websites mit 50 Seiten haben meistens kein Crawl-Budget-Problem. Online-Shops mit 5.000 Produktseiten oder Jobportale mit täglich neuen URLs sehr wohl.
Wenn Googlebot sein Crawl Budget aufgebraucht hat, bevor er alle Seiten einer Website gecrawlt hat, bleiben neue oder aktualisierte Seiten wochenlang unkontrolliert. Das ist kein theoretisches Szenario — bei einem Schweizer Online-Shop mit rund 3.500 Produktseiten beobachteten wir, dass neue Produkte erst nach drei bis vier Wochen in den Google-Suchergebnissen erschienen, obwohl sie sofort publiziert wurden. Die Ursache: Filterseiten und URL-Parameter verschwendeten über 40 Prozent des verfügbaren Crawl-Budgets auf irrelevante Duplikat-URLs.
Drei Massnahmen verbessern das Crawl-Budget gezielt. Erstens: Unnötige URLs aus dem Crawling ausschliessen — Filterseiten, Parameter-Kombinationen, interne Suchergebnis-URLs. Zweitens: Schnelles Hosting und niedrige TTFB-Werte. Googlebot erhöht die Crawlfrequenz bei schnellen Servern messbar — das ist kein Mythos, sondern ein dokumentiertes Verhalten. Drittens: Interne Links auf wichtige Seiten konzentrieren. Seiten, auf die viele interne Links zeigen, crawlt Googlebot häufiger.
HTTP-Statuscodes: Was Googlebot wirklich sieht
Jede Anfrage, die Googlebot für die Google Indexierung an Ihren Server schickt, bekommt eine Antwort — und diese Antwort enthält einen dreistelligen Statuscode. Diese Codes sind direkte Signale, die bestimmen, was Google mit der URL macht. Viele Website-Betreiber kennen 404 — aber die anderen Codes und ihre SEO-Auswirkungen sind weniger bekannt.
Ein Fall aus unserer Praxis: Eine Schweizer Dienstleistungswebsite hatte nach einem Relaunch 312 URLs mit 302-Weiterleitungen (temporäre Weiterleitung) statt 301-Weiterleitungen (permanent). Der Unterschied für Google: Bei 302 überträgt Google die Ranking-Signale der alten URL nicht vollständig auf die neue. Die Website verlor deshalb nach dem Relaunch für mehrere Wochen die Hälfte ihrer Sichtbarkeit — bis wir die Weiterleitungen korrigierten.
Die JavaScript-Falle: Wenn Google den Inhalt erst Sekunden später sieht
Das ist das technische SEO-Problem, das in der Schweizer E-Commerce-Praxis am stärksten unterschätzt wird. Viele moderne Websites — besonders Shops auf Shopify, WooCommerce mit Heavy-Themes oder Angular/React-Frontend-Systemen — laden ihren eigentlichen Inhalt nicht im rohen HTML. Stattdessen liefert der Server zunächst eine leere HTML-Hülle aus, und das JavaScript baut danach erst den Inhalt auf.
Für einen menschlichen Besucher macht das keinen Unterschied — der Unterschied in der Ladezeit ist minimal, und das Ergebnis sieht identisch aus. Für Googlebot macht es einen erheblichen Unterschied. Googlebot liest das rohe HTML in Phase 2. Danach reiht er die URL in eine Warteschlange für das JavaScript-Rendering ein — Phase 3. Diese zweite Phase findet nicht unmittelbar statt, sondern mit einer Verzögerung von Stunden bis Tagen. Und während dieser Verzögerung sieht Google Ihren Content schlicht nicht.
Verzögerung zwischen Crawl und vollständiger JS-Rendering — typische Werte je nach Framework
Richtwerte aus Log-File-Analysen und Google-Dokumentation. Variiert je nach Domain-Autorität und Server-Geschwindigkeit.
Wie erkennt man, ob die eigene Website davon betroffen ist? Der direkteste Test: Google Search Console → URL-Inspektion → URL eingeben → «Gerendertes HTML» anzeigen. Wenn dieses gerenderte HTML deutlich weniger Inhalt enthält als die Seite im Browser zeigt, hat man ein JavaScript-Rendering-Problem. Alternativ öffnet man Chrome DevTools, deaktiviert JavaScript unter Einstellungen → Debugger und lädt die Seite neu. Was dann noch angezeigt wird, entspricht ungefähr dem, was Googlebot in Phase 2 sieht.
Typisches Schweizer E-Commerce-Szenario: Ein Zürcher Modehandel auf WooCommerce verwendete ein Page-Builder-Theme, das Produktbeschreibungen, Preise und Bewertungen über JavaScript nachlädt. Google sah bei der initialen HTML-Anfrage pro Produktseite nur den Header, den Produkttitel und die Breadcrumbs. Alles andere — Beschreibung, Preisinformation, Bewertungsanzahl, Cross-Sell-Produkte — entstand erst nach dem Rendering. Ergebnis: Über 600 Produktseiten erschienen in den Suchergebnissen als inhaltlich fast leer. Keines dieser Produkte rankte für spezifische Produktanfragen. Die Lösung war nicht teuer: Wechsel zu einem SSR-kompatiblen Theme und serverseitiges Laden der kritischen Produktdaten. Nach acht Wochen rankten 180 der 600 Produktseiten für relevante Longtail-Suchanfragen.
Die KI-Bot-Perspektive: Was OAI-SearchBot auf Ihrer Website sucht
Crawling und Google Indexierung sind 2026 kein Google-exklusives Thema mehr. Laut einer Analyse von Botify und Nectiv, die 7 Milliarden OpenAI-Logeintrage auswertete, hat OpenAI seinen Web-Crawl seit August 2025 verdreifacht. Und dabei hat sich etwas Grundlegendes verändert: OpenAI crawlt jetzt mehr für Echtzeit-Suche als für Modell-Training — eine direkte Konsequenz des GPT-5-Launches und der steigenden Nutzung von ChatGPT Search.
OpenAI betreibt dabei drei verschiedene Bots mit unterschiedlichen Aufgaben. GPTBot sammelt Trainingsdaten für zukünftige Modelle. OAI-SearchBot crawlt live für Echtzeitanfragen in ChatGPT Search — er entscheidet also, ob Ihre Website als Quelle in KI-Antworten erscheint. ChatGPT-User schliesslich ist ein nutzergesteuerter Bot, der auf Anfrage einzelne Seiten abruft. Alle drei lassen sich über robots.txt separat steuern — und das macht eine bewusste Entscheidung nötig.
Die drei OpenAI-Bots und ihre robots.txt-Steuerung
| Bot | Aufgabe | robots.txt-Tag | Empfehlung für seo-partner.ch |
|---|---|---|---|
| OAI-SearchBot | Echtzeit-Crawl für ChatGPT Search — entscheidet über Zitierbarkeit in Live-Antworten | OAI-SearchBot | Allow: / — Sichtbarkeit in ChatGPT Search |
| GPTBot | Trainingsdaten-Sammlung für zukünftige OpenAI-Modelle | GPTBot | Eigene Entscheidung — Blocking verhindert Training, nicht Search |
| ChatGPT-User | Nutzergesteuert: ruft Seiten auf Anfrage in ChatGPT-Sitzungen ab. Respektiert robots.txt seit Dezember 2025 nicht mehr offiziell | Kein verlässliches Tag mehr | Server-seitiges Rate-Limiting empfohlen |
| PerplexityBot | Crawlt für Perplexity AI Search | PerplexityBot | Allow: / — Zitierbarkeit in Perplexity |
| ClaudeBot | Anthropics Trainingscrawler | ClaudeBot | Eigene Entscheidung — ähnlich wie GPTBot |
Dabei unterscheidet sich die Lesweise von OAI-SearchBot von Googlebot in einem wichtigen Punkt: Der OpenAI-Bot sucht keine Keyword-Dichte, keine Backlinks, keine Page Rank-Signale. Er sucht klare, faktisch präzise Antworten auf Fragen. Strukturierte Daten (Schema.org), direkte Formulierungen, klar benannte Autorenschaft und FAQ-Blöcke sind deshalb besonders wirksam — weil sie die Antworten so formatieren, dass der Bot sie leicht extrahieren kann.
Ein weiteres Detail aus der BrightEdge-Analyse: Google NotebookLM wuchs zwischen November 2025 und Februar 2026 um 144 Prozent. Das ist ein Bot, den Forscher, Analysten und Wissensarbeiter nutzen, wenn sie Dokumente analysieren. Für Schweizer B2B-Unternehmen, Kanzleien und Beratungsgesellschaften ist das ein wachsender Kanal, der bisher kaum beachtet wird. Zugängliche, gut strukturierte Inhalte haben dabei einen direkten Vorteil — unabhängig davon, wie sie für klassische Suchmaschinen optimiert sind.
Wer seine Website für diese neue Crawler-Generation bereit machen möchte, sollte ausserdem die Datei llms.txt kennen. Sie liegt unter ihredomain.ch/llms.txt und liefert KI-Agenten eine kuratierte Karte der wichtigsten Inhalte — besonders nützlich für Websites mit Dokumentationen, API-Informationen oder strukturiertem Fachwissen. Als SEO-Agentur für den Schweizer Markt empfehlen wir die Einrichtung dieser Datei allen Mandanten, die GEO-Sichtbarkeit aufbauen möchten. Wie GEO und klassisches SEO zusammenhängen, erklärt unser SEO-Grundlagen-Leitfaden.

Google Indexierung prüfen und verbessern — der praktische Ablauf
Sobald man die fünf Phasen versteht, wird klar, wo man ansetzen muss. Dieser Ablauf orientiert sich an dem, was in unserer Beratungspraxis den grössten Unterschied macht — sortiert nach Dringlichkeit.
Um die Google Indexierung Ihrer Website zu prüfen, beginnen Sie mit der Google Search Console. Der Bericht «Seiten» zeigt, wie viele URLs indexiert sind, wie viele ausgeschlossen wurden und warum. Die häufigsten Ausschlussgründe in unseren Audits: «Entfernt durch noindex-Tag» (oft unbeabsichtigt), «Seite mit Crawling-Fehler» und «Nicht gefunden (404)». Jeder dieser Punkte hat eine andere Ursache und braucht eine andere Lösung.
Danach prüfen Sie Ihre Robots.txt direkt im Browser — rufen Sie ihredomain.ch/robots.txt auf und lesen Sie jede Zeile. Suchen Sie nach Disallow: / ohne einschränkenden Pfad — das ist der häufigste fatale Fehler. Prüfen Sie auch, ob der Sitemap XML-Pfad korrekt eingetragen ist und ob er auf eine zugängliche URL zeigt.
Für JavaScript-Websites führen Sie den URL-Inspektionstest in der Search Console durch: URL eingeben, auf «Live-URL testen» klicken, dann «Gerendertes HTML» öffnen. Vergleichen Sie dieses gerenderte HTML mit dem, was Sie im Browser sehen. Wenn wichtige Inhalte — Produktbeschreibungen, Preise, H1-Überschriften, Haupttext — im gerenderten HTML fehlen, haben Sie ein JavaScript-Problem, das prioritär behoben werden muss.
Abschliessend: Reichen Sie eine saubere Sitemap ein und beobachten Sie die Indexierungsquote über vier Wochen. Eine gesunde Website sollte mehr als 80 Prozent der eingereichten Sitemap-URLs indexiert haben — das ist ein verlässlicher Massstab für gesunde Google Indexierung. Liegt die Quote deutlich darunter, signalisiert das entweder ein Qualitätsproblem (Seiten sind zu dünn) oder ein technisches Problem (Seiten sind nicht erreichbar). Die Google Search Console zeigt für beide Szenarien unterschiedliche Fehlercodes — und gibt damit den direkten Hinweis auf den richtigen Reparaturweg.
Möchten Sie wissen, wie viele Ihrer URLs Google tatsächlich indexiert hat und wo die Crawling-Probleme auf Ihrer Website liegen? Eine kostenlose Erstanalyse gibt Ihnen Klarheit — ohne Fachjargon, ohne Verpflichtung.
Häufige Fragen zu Crawling und Google Indexierung
Wie lange dauert es, bis Google eine neue Seite indexiert?
Das hängt von der Domain-Autorität und der Crawl-Frequenz ab. Etablierte Websites mit regelmässigem Traffic können neue Seiten innerhalb von Stunden bis wenigen Tagen indexiert sehen. Neue Domains oder schwach verlinkte Seiten warten manchmal zwei bis vier Wochen. Den Prozess beschleunigen Sie durch: Sitemap einreichen, den «URL-Überprüfung»-Tool in der Google Search Console nutzen («Indexierung beantragen») und interne Links von bereits indexierten Seiten auf die neue URL setzen. Eine URL, auf die keine internen Links zeigen, findet Googlebot oft gar nicht.
Was ist der Unterschied zwischen Crawling und Indexierung?
Crawling bedeutet, dass Googlebot eine URL besucht und ihr HTML herunterlädt. Indexierung bedeutet, dass Google diese URL nach Bewertung in seine Suchdatenbank aufnimmt und für Suchanfragen berücksichtigt. Eine URL kann gecrawlt, aber nicht indexiert werden — etwa weil sie einen noindex-Tag hat, weil ihr Inhalt als zu dünn gilt oder weil Google sie als Duplikat einer anderen Seite einstuft. Umgekehrt kann eine URL im Index sein, ohne regelmässig gecrawlt zu werden — besonders bei schwachen oder veralteten Seiten.
Kann ich Google zwingen, meine Seite zu indexieren?
Nein — Google entscheidet eigenständig, welche Seiten es indexiert. Was Sie tun können: Die Indexierung beantragen über das URL-Inspektionstool in der Google Search Console. Das beschleunigt den Prozess, garantiert aber nicht die Aufnahme. Google indexiert keine Seiten, die es für qualitativ unzureichend hält — etwa Seiten mit extrem wenig Inhalt, identischem Content wie andere Seiten oder fehlender inhaltlicher Eigenständigkeit. Technische Barrieren wie fehlerhafte robots.txt-Einträge oder Server-Fehler blockieren die Indexierung ebenfalls — diese müssen zuerst behoben werden.
Sollte ich OAI-SearchBot in robots.txt zulassen oder blockieren?
Für die meisten Unternehmen empfehlen wir, OAI-SearchBot zuzulassen. Dieser Bot crawlt für ChatGPT Search — also für Echtzeit-Antworten in ChatGPT. Wer ihn blockiert, erscheint nicht als Quelle in ChatGPT Search-Ergebnissen. GPTBot hingegen — der Trainingsdaten-Crawler — ist eine andere Entscheidung: Blockieren verhindert, dass Ihre Inhalte zukünftige OpenAI-Modelle trainieren, hat aber keinen direkten Einfluss auf ChatGPT Search-Zitierbarkeit. Für contentbasierte Unternehmen ist die Frage, ob sie Trainingsdaten bereitstellen möchten, eine strategische — kein technisches SEO-Thema.
Wann ist Crawl Budget ein echtes Problem?
Das Crawl Budget ist für kleine KMU-Websites mit 20 bis 100 Seiten kein relevantes Problem — Googlebot crawlt diese Seiten problemlos vollständig. Relevant wird das Thema ab etwa 1.000 bis 2.000 URLs, besonders wenn viele davon durch Parameter, Filter oder Paginierung entstehen. Ein klares Warnsignal: Wenn neue Seiten nach mehr als vier Wochen immer noch nicht in der Google Search Console als indexiert erscheinen, obwohl technisch alles korrekt ist. Ein weiteres Signal: Eine hohe Anzahl von «gecrawlt — aktuell nicht indexiert»-URLs in der Search Console, verbunden mit einer stagnierenden Indexierungsquote.
Haben Sie Fragen zur Google Indexierung Ihrer Website — oder wollen Sie wissen, welche Crawling-Probleme Ihre Seite aktuell hat? Sprechen Sie uns an. Wir schauen es kostenlos und ohne Verpflichtung gemeinsam an.